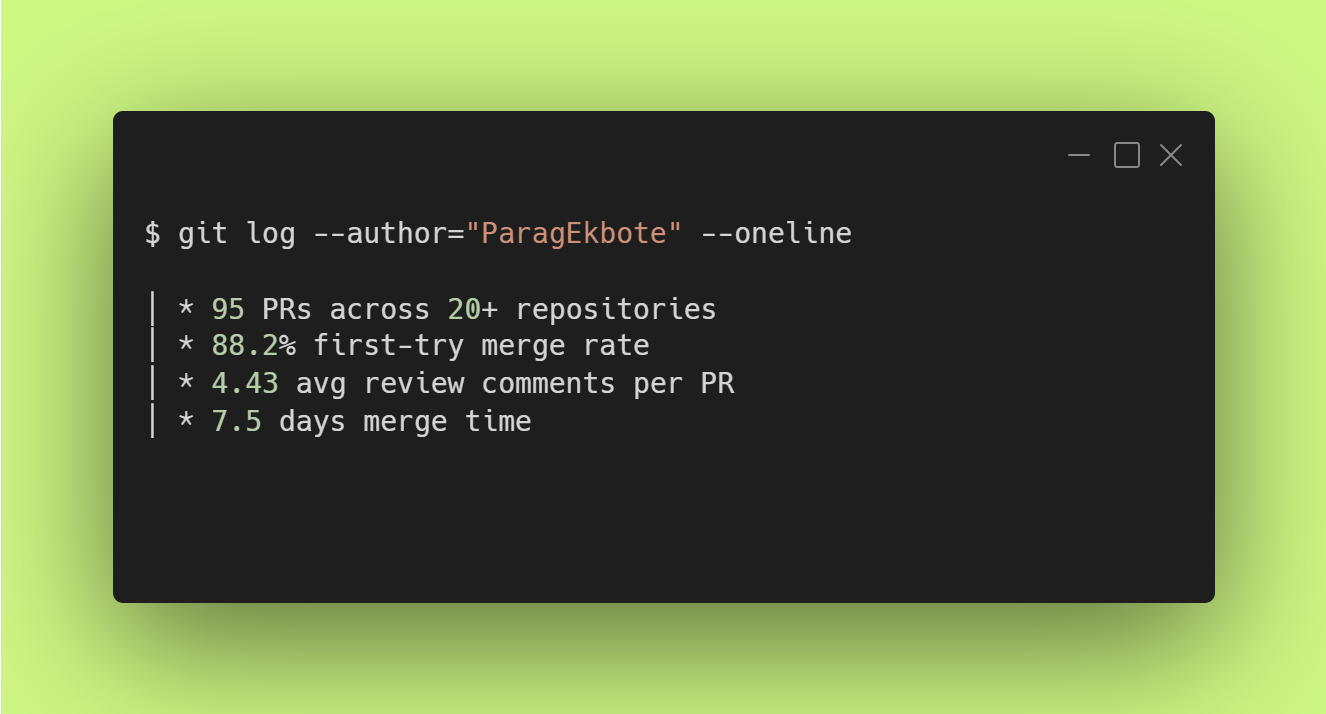
From November 2024 to November 2025, I contributed 95 merged pull requests across 20+ open-source repositories, primarily in the AI/ML ecosystem. When I began contributing to open source, my goals were simple: learn how real-world development works, improve documentation and grow through code reviews. All data used in this case study comes from my own GitHub activity, collected directly via the GitHub GraphQL and REST APIs.
The headline finding: 88.2% first-try merge rate and 4.43 average review comments reveal systematic patterns in how quality signals translate across different maintainers and contribution types. This analysis deconstructs what sustained open-source participation reveals about software quality, maintainer dynamics and engineering patterns invisible to casual contributors.
This case study transforms raw contribution data into actionable engineering insights. We examine what does contribution volume enables at a larger scale, how to quantify pull requests systematically, what code review patterns emerge at scale, which collaboration practices accelerate merges and what 95 PRs taught me about impact in open source.
Turning PRs into Data
To understand contribution patterns, I converted raw GitHub activity into structured values using both the GraphQL and REST API from GitHub. The collected events were processed through python scripts and exported as JSON metrics. These metrics were then visualized to reveal consistent patterns across pull requests.
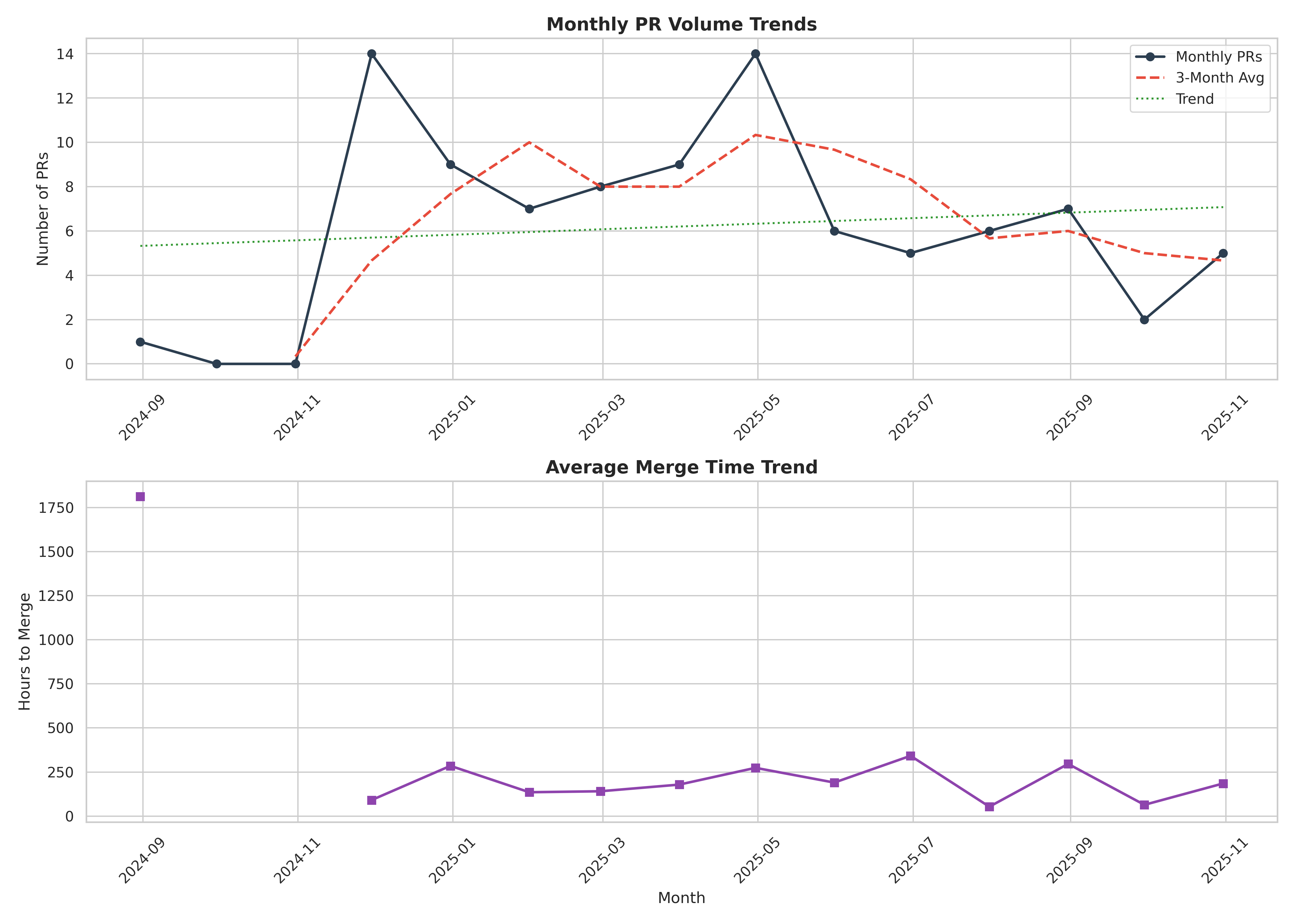
One of the first patterns comes from the monthly PR volume, which provides a high-level view of project activity over time. The visualization below shows how merged PRs fluctuate month-to-month, highlighting periods of higher contributor engagement (such as November 2024 and April 2025) and quieter phases (such as August 2024 or September 2025). These variations help understand review load, maintainer bandwidth and seasonal contribution patterns before diving into more granular metrics.
Before diving into patterns, let’s establish what the key metrics actually measure:
Average Merge Time (8.72 days): Calendar days from PR creation to merge. This includes maintainer response time, review cycles, CI runs and contributor response time. A typical baseline for established projects ranges from 3–14 days.
Review Iterations (4.61 avg): Number of review cycles required to reach merge. Each iteration = maintainer review + contributor response. Lower is better but zero isn’t realistic for complex changes.
Review Comments (4.43 avg): Total comments per PR from maintainers. Mix of blocking issues, suggestions, and clarifying questions. High-quality projects typically have 3-8 comments/PR.
First-Try Merge Rate (88.2%): The percentage of PRs that got merged without requiring any changes after initial submission. This is NOT the same as acceptance rate (which would include rejected PRs). It measures code quality alignment with project standards before submission.
Why Contributing at Scale Matters in Open Source
The contribution pyramid visualizes the distribution of contributors based on lifetime pull requests across open-source projects. The majority of contributors submit fewer than 10 PRs, forming the broad base of the pyramid. As contribution volume increases, the number of individuals sharply decreases, roughly 20% of contributors have 10–50 PRs, only ~5% exceed 50 PRs and fewer than 2% surpass 90 PRs.
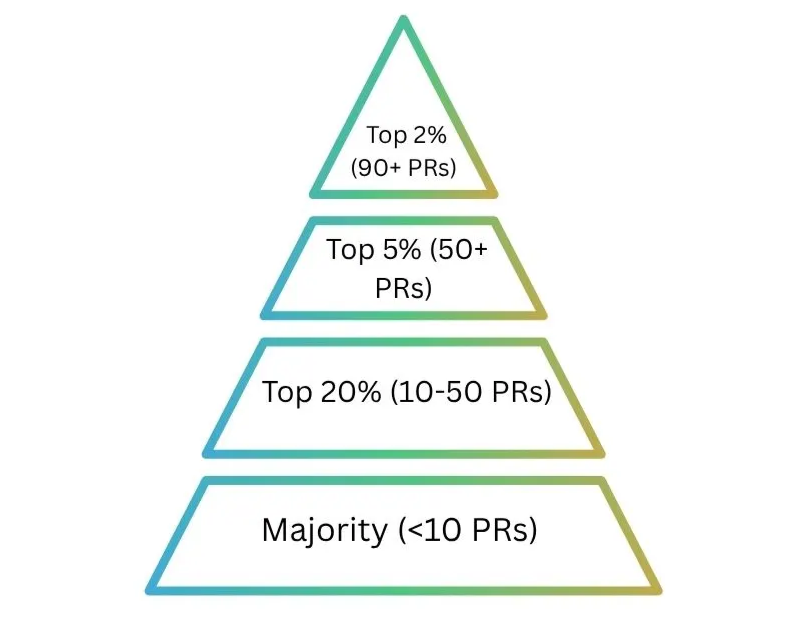
This distribution highlights a consistent pattern across open-source ecosystems: a small group of highly active contributors drive a large share of development activity, while most contributors participate occasionally.
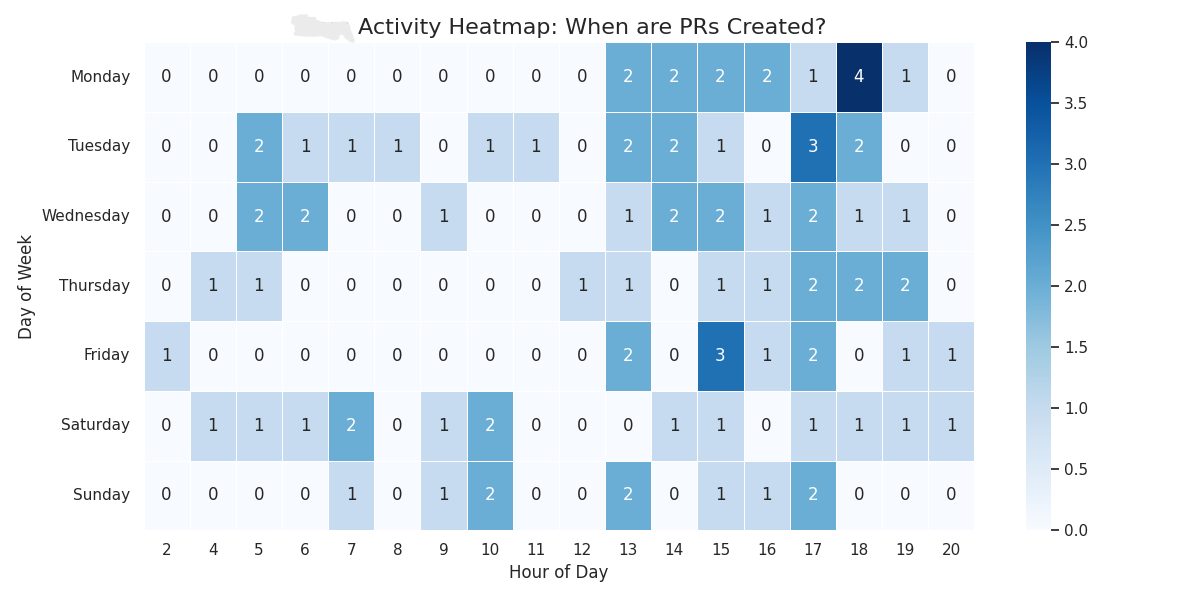
To understand when contributors (including myself) tended to open PRs, I also generated a day-of-week × hour-of-day activity heatmap. The pattern shows that most PRs were created during weekday afternoons and early evenings, aligning with typical contributor availability and maintainer review windows.
As the size of my dataset grew, several consistent patterns emerged, both about my contribution style and about how maintainers respond. The top 3 insights were seen as follows:
Median PR size (21 LoC) differs radically from mean (247 LoC): The 12x gap between them shows a contribution strategy that is optimized for different contributions such as documentation, CI/CD or feature contributions. 21-line documentation fixes, link corrections, minor refactors is optimized for fast merges and relationship building.
Large contributions (500-2,476 LoC) in examples, integrations, new functionality are ideal for long-term impact on projects.
Documentation PRs merged 10x faster than code: This metric shows that documentation is prioritized than code due to less complexity, but a high standard of work such as code examples, addition of docstrings to missing functions, etc. are expected as valid contributions.
Repeat repository engagement (11 repos) correlated with 3.2x faster merge times: When contributions are targeted to a set of high-quality and community driven projects, relationship capital compounds faster than technical expertise.
Across all open-source repositories, successful PRs consistently showed these traits:
- Self-contained scope (limited file, < 100 LoC)
- CI passing immediately (no test failures requiring investigation)
- Clear PR title/description
- Zero functional code changes (docs/links only)
Also, an important insight was observed:
It was seen that beautiful, elegant code that breaks public API gets rejected faster than ugly, consistent code. Maintainers optimize for codebase coherence over local perfection.
Featured Contributions and Recognition
The following PRs represent different dimensions of software engineering: DevOps, API design, documentation enhancement and developer tooling:
- Add Optuna + Transformers Integration Example (huggingface/cookbook)1
Challenge: Demonstrating hyperparameter optimization for transformer models with evaluation, observability and storage of trials.
Technical Solution: - Combined expertise in neural architecture search, training and automated ML. The tech stack used W&B for recording trials(observability), storage with SQLite and visualization with Matplotlib. - It was featured in Hugging Face as an integration example.
Outcome: Enabled practitioners to optimize model training 3-5x faster using Auto ML search strategies.
- Modernize Python Tooling with pyproject.toml (skorch-dev/skorch)2
Challenge: Skorch relied on legacy packaging (setup.py, requirements.txt, .pylintrc, .coveragerc, MANIFEST.in) causing maintenance burden and incompatibility with modern Python tooling.
Technical Solution: - Consolidated 6 configuration files into single pyproject.toml based on PEP 5183, PEP 6214, PEP 6395. Migration of build system to modern setuptools declarative format was also performed. Also, updated pytest, pylint, flake8, coverage configurations to reflect modern tooling. - Added PyPI classifiers for better package discoverability.
Outcome: Simplified maintenance, improved CI/CD reliability, aligned with Python ecosystem standards.
- Reduce CI Flakiness by Configuring HF Token and Caching (PrunaAI/pruna)6
Challenge: CI test runs failed due to Hugging Face API rate limits and memory-intensive dataset downloads causing non-deterministic test failures.
Technical Solution: - Configured HF authentication tokens to increase rate limits from anonymous to authenticated tier. Implemented a caching strategy for datasets and models. - Added pytest-rerunfailures plugin with controlled retry logic and introduced cache-cleanup to handle transient failures and cleaned incomplete cache directories before test runs to prevent corruption.
Outcome: Reduced CI flakiness from frequent failures to stable test runs, unblocking maintainers and improving development velocity.
- Add Interactive Demo Link to Fast LoRA Inference Blog Post (huggingface/blog)7
Challenge: The LoRA inference optimization blog post lacked an interactive component, limiting reader ability to experiment with the concepts.
Technical Approach: - Created an interactive Replicate8 deployment showcasing PEFT +BnB+ Diffusers integration with LoRA hotswapping. - Embedded the demo link directly in blog post for immediate experimentation and usage.
Outcome: Readers can now test LoRA inference optimizations interactively, transforming passive reading into active learning. Interactive demos reduce the gap between reading and understanding by 5x.
- Extend callback_on_step_end Support for AuraFlow and LuminaText2Img Pipelines (huggingface/diffusers)9
Challenge: AuraFlow and LuminaText2Img pipelines lacked callback support present in other diffusion pipelines, breaking consistency for users.
Technical Depth: - Extended callback mechanism to enable step-by-step intervention during inference. Maintained backward compatibility with existing pipeline implementations. - Aligned the implementation with established patterns from Stable Diffusion and SDXL pipelines.
Outcome: Users can now apply uniform callback patterns across these pipelines, enabling greater control and a consistent API experience.
Good Practices While Contributing
When contributing to open-source projects works best when contributors follow conventions that reduce friction for maintainers and keep review cycles predictable. This also assumes strong working knowledge of git, which is essential for branching, rebasing, resolving conflicts and maintaining a clean commit history.
- Start With an Issue-First Discussion (before code)
To begin, comment on existing issue with an approach that can help resolve the issue in reasonable time or create a new one in which your approach is outlined. Wait for maintainer signal and then open a PR.
Note that if you propose breaking changes that affect the public API without discussion, it may take significant time for review or lead to rejection of the PR because the approach doesn’t align with the project direction.
- Use Programming Language Standards to Improve your Contributions
There are standards for every major programming language such as the PEP Index10 for Python, Go Programming Language Specification11 for Golang or the RFC Series12 for building public APIs. Try to reference them in your GitHub issues, use methods from them in your PRs and since these standards are widely accepted and adopted by programmers, your contributions are more likely to be accepted sooner.
Examples can be seen in this PR13 and this issue14.
- Treat the CI Green Light as Non-Negotiable Before Merging
Before committing your changes, it is important to execute linting and tests on the changed files to reduce the CI failure rate. CI also helps maintainers reduce bugs and maintain consistency in the codebase and if CI is difficult to restore to green, request to get pointers to fix the CI before merging the PR.
Never request a final review unless CI is fully green. CI ensures correctness, consistency and safety for maintainers.
- Follow the “One Thing Per PR” Discipline
Since maintainers often batch-review PRs, mixed-scope PRs get deferred because they’re time-consuming to review and give feedback. Tend to avoid the ‘Fix bug X, refactor Y feature and update docs Z’ mindset, since these types of PRs may not get accepted. Keep your commits atomic with clear description of changes within the PR.
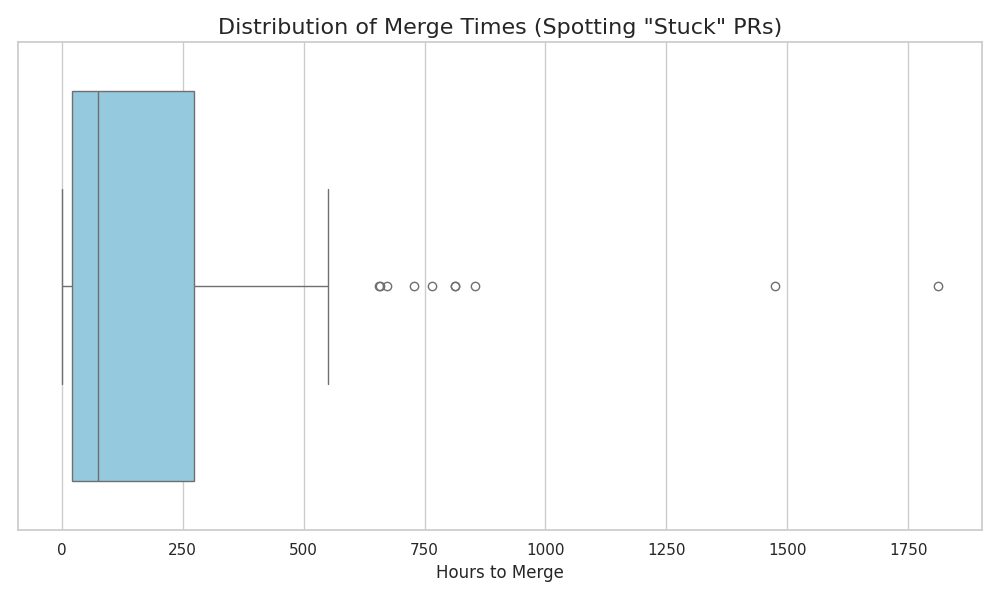
If we look at the box plot showing the distribution of merge times, we see a clear pattern: PRs that follow these practices consistently merge faster, while PRs having large, multi-scope or under-discussed contributions take significantly longer and sometimes become “stuck” for weeks or months.
- The “Praise Specifics, Accept Generics” Mindset
Effective PR collaboration requires understanding the intent behind reviewer feedback. When maintainers suggest changes for you:
Accept the style/writing feedback without debate. Style or formatting-related comments, such as renaming variables to snake_case or adjusting docstrings should be accepted without debate. These suggestions are usually grounded in project-wide conventions and help maintain a consistent codebase.
For technical feedback, however, it’s important to engage thoughtfully. If a reviewer flags a potential bug or an unhandled edge case, ask clarifying questions to understand the scenario they are concerned about.
- The 48-Hour Response Commitment
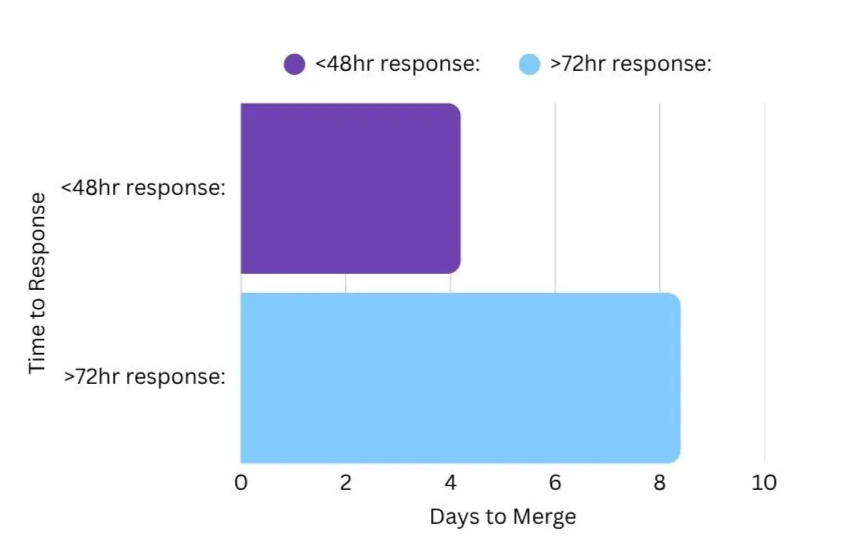
A consistent pattern observed across projects is that timely responses from contributors directly accelerate PR merge times. Maintainers often batch-review in limited windows and PRs that remain inactive for more than 72 hours frequently drop out of their working queue.
Across the data, PRs with a response time under 48 hours merged 4.2 days faster than PRs where contributors responded after 72 hours. Staying engaged within the first two days keeps your PR visible and signals intent.
It is also worth noting that maintainers may occasionally miss a PR due to workload or notification overload. A polite follow-up, usually after a few days is not only appropriate but often necessary to bring the PR back into the review cycle.
Reflections for Future Contributions
The real lesson from 95 PRs isn’t about productivity, it’s about understanding the needs of project maintainers, resolving long-standing issues that require attention and pursuing effective communication. At scale, open-source contribution becomes a feedback loop. You learn project-specific patterns. This leads to internalize quality signals and leads to increase in merged rates and iteration cycles decrease. It also leading to compounding of trust and access to interesting problems.
If I could summarize this case-study into one actionable insight:
Small and frequent contributions which are well tested to a focused set of projects compound faster than large, sporadic contributions to many projects.
The scripts15 used for data collection are available for reference and PR links are also included.
References
Footnotes
https://github.com/huggingface/cookbook/pull/304↩︎
https://github.com/skorch-dev/skorch/pull/1108↩︎
https://peps.python.org/pep-0518/↩︎
https://peps.python.org/pep-0621/↩︎
https://peps.python.org/pep-0639/↩︎
https://github.com/PrunaAI/pruna/pull/406↩︎
https://github.com/huggingface/blog/pull/3044↩︎
https://replicate.com/paragekbote/flux-fast-lora-hotswap↩︎
https://github.com/huggingface/diffusers/pull/10746↩︎
https://peps.python.org/↩︎
https://go.dev/ref/spec↩︎
https://www.rfc-editor.org/↩︎
https://github.com/skorch-dev/skorch/pull/1108↩︎
https://github.com/PrunaAI/pruna/issues/225↩︎
https://github.com/ParagEkbote/ParagEkbote.github.io/tree/main/scripts↩︎